
If you read my previous detailed SEO Website Audit Guide you will see that I covered almost every factor that goes into doing an SEO audit of a website.
However, I did not walk you through step-by-step in the execution process of the audit.
So, in the coming weeks, I will release a series of step-by-step walk-throughs of all the various factors that go into the an SEO audit.
In this post, I will start by showing you the exact step by step method that goes into performing all the steps of an on-page technical SEO audit.
Lets get started…
Here are all the key technical factors that go into performing an SEO Audit that we will cover in this tutorial.
All these technical factors can affect anywhere between 15% to 100% of your rankings.
If you get it right it can affect 15% of your rankings, but if you get it wrong you can be hit at 100% (all your rankings).
Lets get on with how you can address each of the above, step by step…
Canonical Pages
What are canonicals?
Put simply… the canonical page is the page you want to be the original “one” version that is represented for the content.
If you have multiple variations of the same content across a series of different pages, the canonical page is that which represents the original page you want Google to index as the “original” or “main” page.
This is how to set it up…
Access any page and look at HTML source code and look for this tag…
<link rel=”canonical” href=”https://mysite.com/and-then-somepage” />
This tag tells google that this page which (the source code the page is a part of) – is a duplicate copy of the original page which is located at the URL shown in the href code above.
If you have multiple other pages with same content then they have to have the href pointing to the URL which is the original page.
Note that – the original page itself can also have this code and simply refer back to itself! The href code will simply be pointing back to the same page itself… and this is ok to do and tells Google that this page is itself the original page!
Make sure the original page URL does not have URL parameters at the end like ?abc=xyz but is a permalink based URL.
Its important to remember that – every page on your website needs this to happen, or very bad negative SEO attacks are possible.
Site Crawl
Crawling is nothing but allowing Google (the GoogleBot) to visit all the pages you want it to see and take the page and put it into its search index – which is essentially Google’s massive database of sites and pages.
Once the page is crawled, it is then submitted for indexing and only when the page is indexed does it have thew ability to compete with other page to rank based on the ranking algorithm!
Google will visit and access each page on your site via the GoogleBot that runs on the “Chrome” browser.
Its important to remember that – Google has said now that their Search Index is “Mobile first” – which means that the browser will crawl your site and view it and index it as if it is on a mobile device!
How it sees your site on mobile is what it will index. So make sure your site is mobile friendly!
How To Check this?
Install Google Search Console on your site and then access the Crawl Section as shown below.
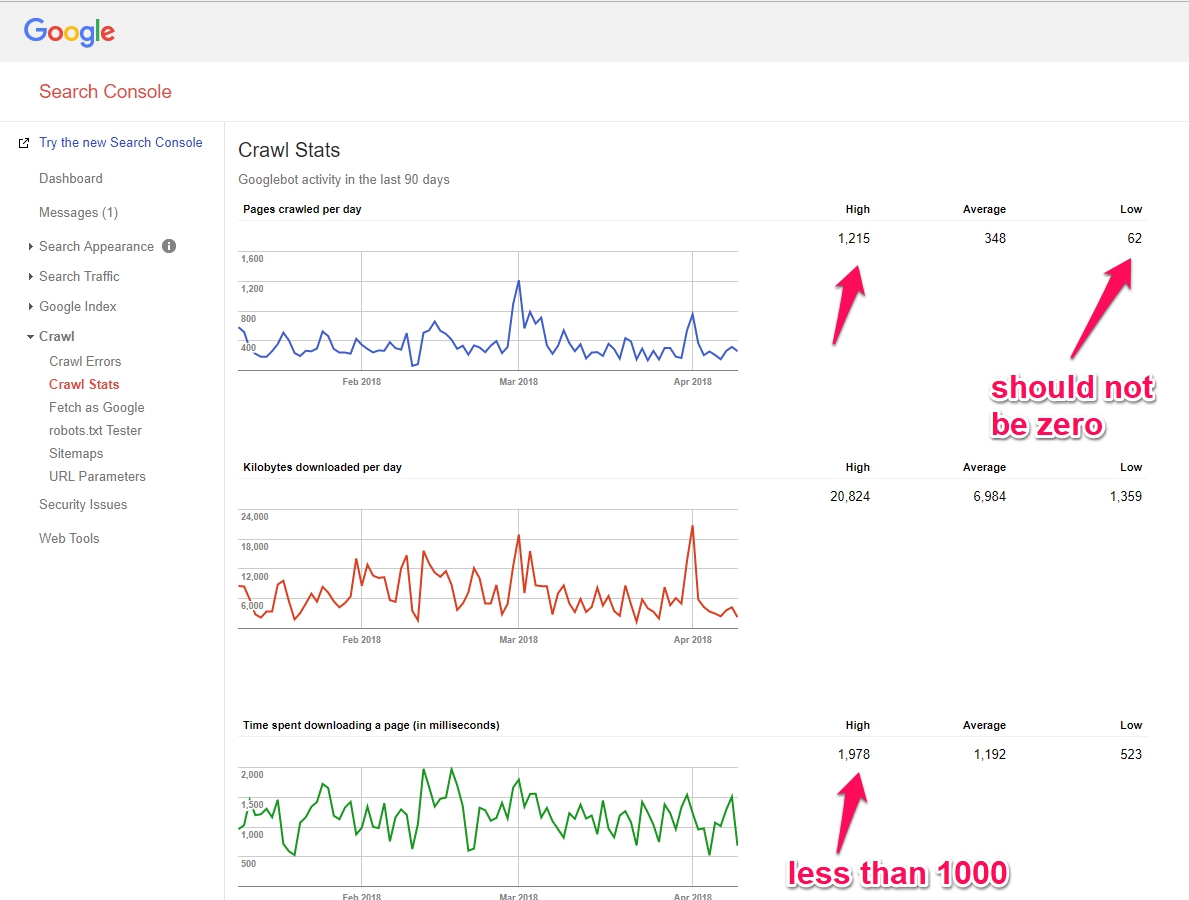
Make sure your High and Low numbers are not zero!
The crawl rate and numbers are determined by a result of the quality of your pages, which is determined by…
- How many pages you have
- How frequently you update your site
- The Speed of your site
Speed is a ranking factor!
Also, check to see how fast Google crawls your site. You want the speed to be below 1 second or 1000 milliseconds.
Indexing and Filtering Pages and Sites
Sites with thin content or duplicate content or low quality content are filtered on the crawl and on the search.
To see what they filtered out in the search just add the URL parameter…
&filter=0
…at the end of a search you do on Google, like so below
How To Check Number of Pages Google has Indexed on Your Site…
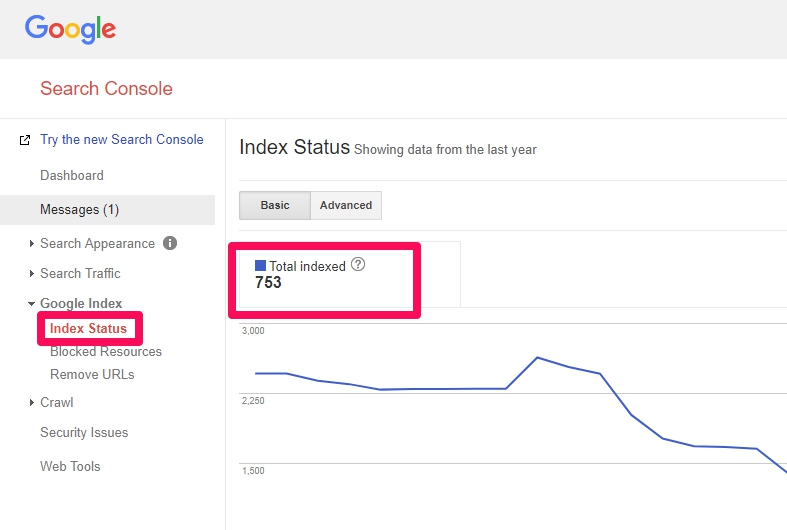
1. From Search Console
Access Google Search Console to see what Google has indexed on your site, just go to Google Webmasters and check the tab as below…
2. Using Google Search
By performing the following search in Google…
site:yoursite.com
…and then go to the URL bar when the search results show up, and add the following parameter at the end of the URL.
&start=990
This will tell you how many pages Google has of your site AFTER filtering out the duplicate content pages!
Important Note: However, this last method does not work for any site that has more than 400 pages!
Server Response Codes
You can check this data inside Google Search Console. The following are the response codes you could get for each page.
These codes are all common for all types of web servers Apache, Microsoft, Nginx etc.
200 – Healthy URL30x – Page moved404 – temporarily gone (can be an issue for cralw budget)410 – permanently gone (therefore this page cant rank or pass juice)50x – Server error! (If you have too many 50x level errors, for over 24 hours – Google will de-index your entire site and when they put it back it may not get back its original rankings)
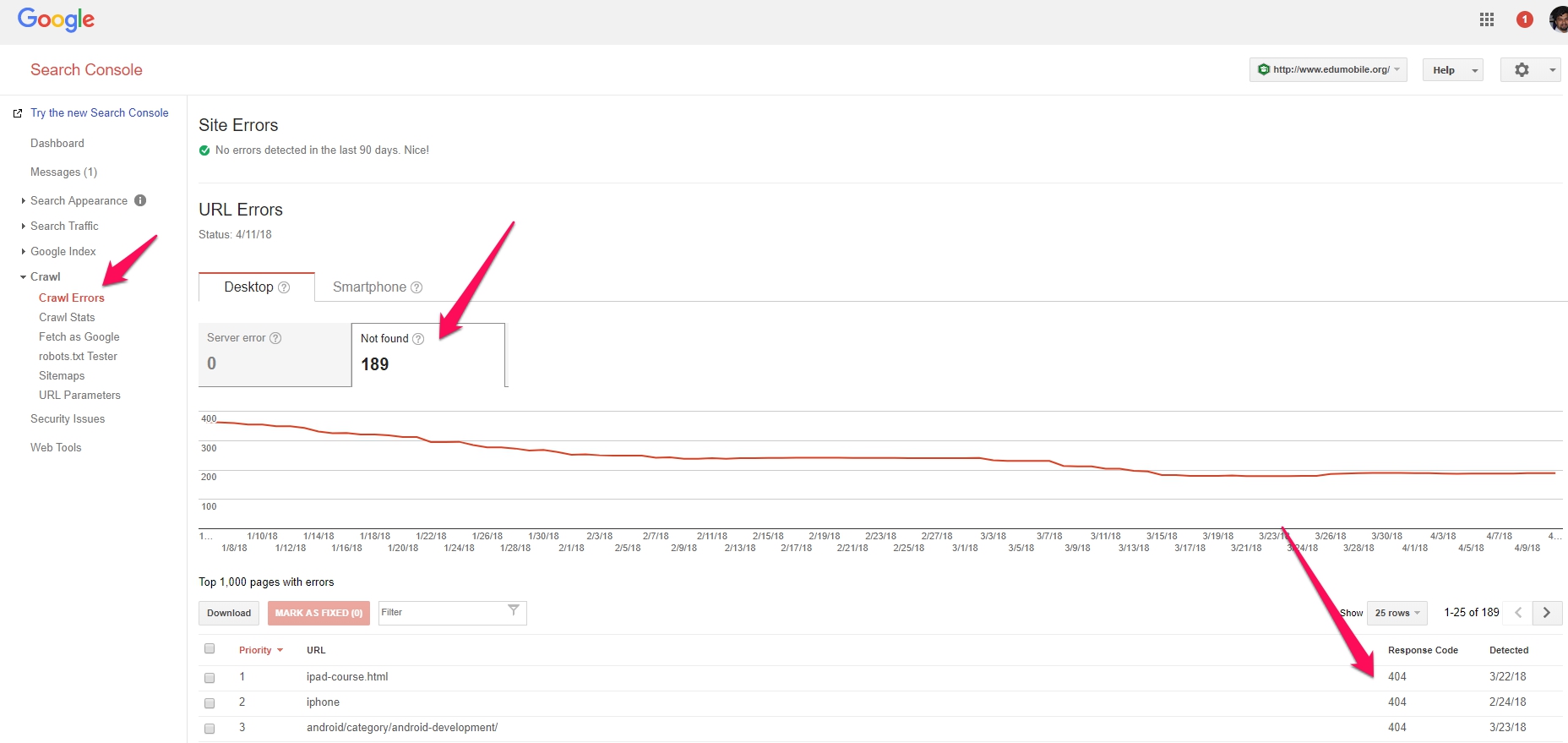
When you find 404 pages – the reason why they exist is because Google found links pointing to these pages. So, if they don’t exist and you want some link juice to other pages of your site – you could simply add a 301 redirect rule for these 404 URL pages to redirect to the page that is similar or the homepage (without having too many 301s to the homepage) – so the link juice from the backlinks now passes through to the new page.
URL Parameter Checks
What is a URL Parameter?
The URL parameter is the variable part at the end after the ? in the example below case. It is the varying part of the URL. It just tells Google to show that page and execute a function as indicated after the symbol ? in this case.
yoursite.com/thepage?type=big
Note, that when Google sees the above URL and compares it with the following URL…
Google sees these as totally different URLs! (different pages)
And so, if they both have the same content, then there could be a duplicate content issue!
If you don’t want the duplicate content issues with URL parameters, then check Google Search Console and check as below. But, only fix things if there are a large number of URL parameters indicated for your site and your site recently dropped in rankings.
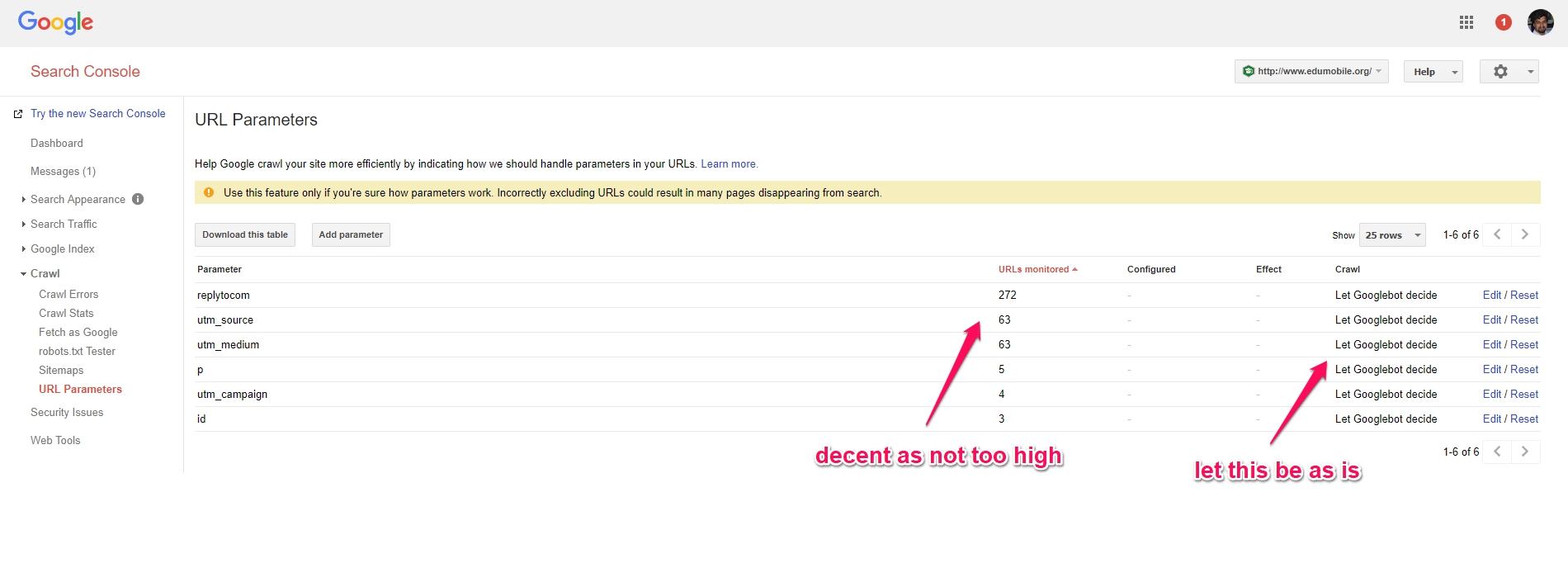
Anyone can link to your pages… and you can get all sorts of URL parameters created as a result – social sites, tracking links, negative SEO links etc.
This can result in site issues in Google Search Console as Google sees all these backlinks to missing pages where it expects pages and if it gets 404 errors you could be in trouble – or – it sees all these pages (200 response) as duplicate pages with same content!
So, how do you fix URL parameter issues?
Use Ayima Crome plugin and see if the page is responding 200 code. If its responding anything other than 200 then you are OK as Google wont spider or index that page.
If this URL – yoursite.com/thepage?type=big
Gives you a 200 return code, you should anyway insert the canonical tag code within the page telling Google what the original page is… yoursite.com/thepage
Robots.txt
This is basically telling Google which files and directories it should crawl and which it should not.
However, you don’t want to block Google from important design resource / code pages on your site as Google wants to see all that data!
Check your robots.txt file to see the code. If you see …
disallow:or –allow: /or –404
… then you are fine!
However, do note that you don’t really need a robots.txt anymore and its not that important SEO factor anymore.
Don’t listen to anyone who tells you otherwise. Google has evolved beyond this and can determine what to do with your site without a robots.txt file.
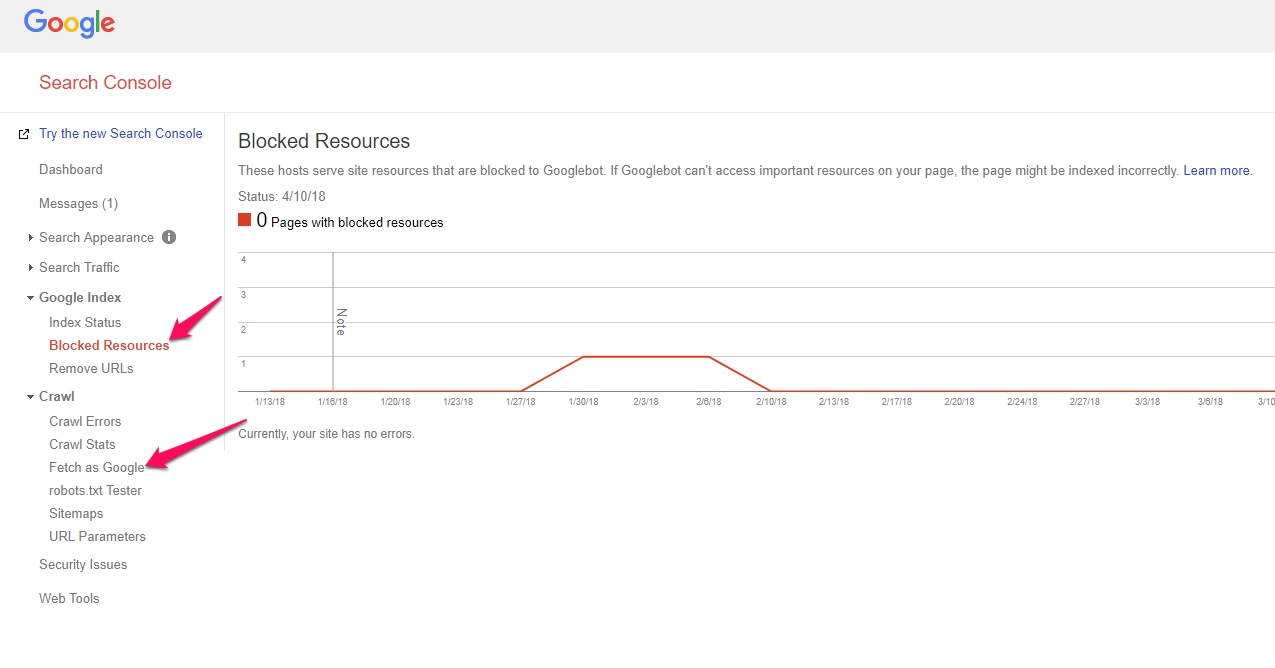
Checking to see the effect of Robots.txt in Search Console
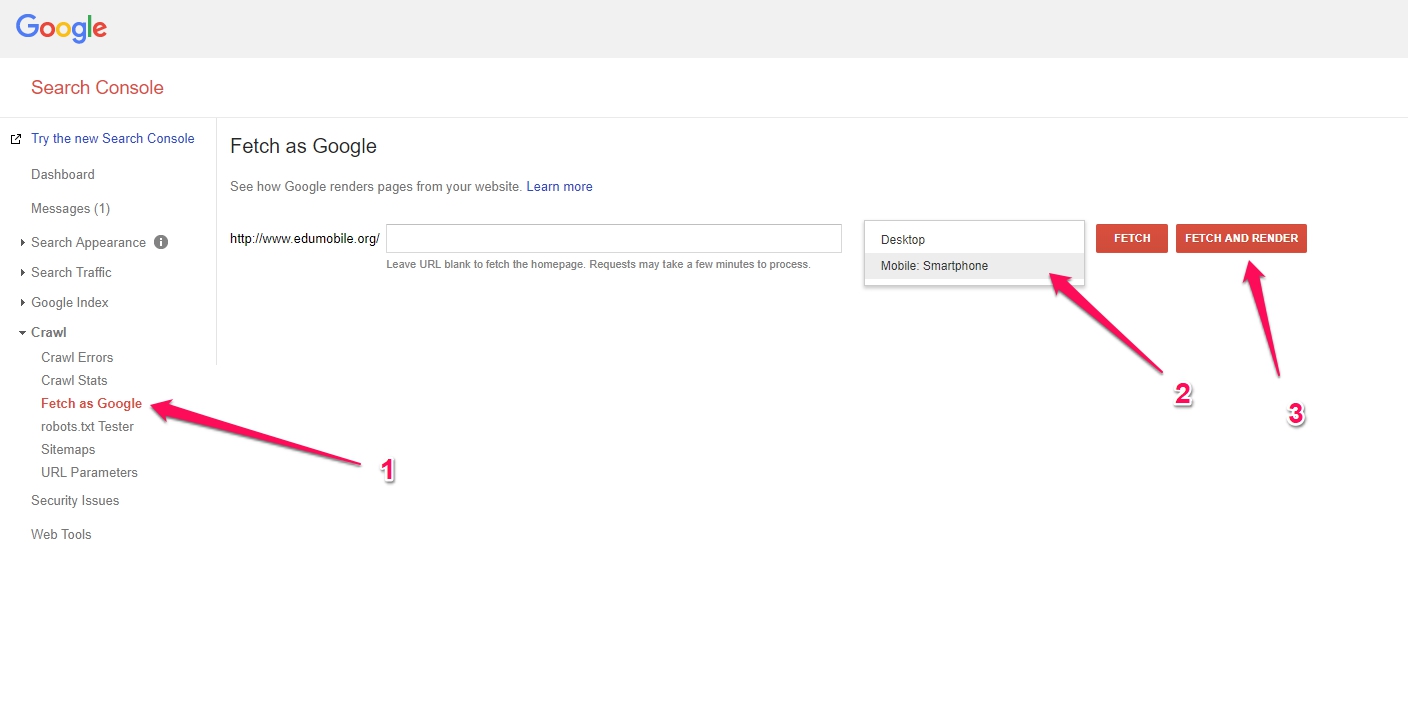
In Search Console you just want to check to see if there are any “blocked resources” and see if any design files are being blocked and you want to “fetch as Google” (choose check as mobile smart phone) – and then make sure that version of mobile is same as desktop.
If you are not using robots.txt file then you don’t need to do this or worry about it!
However, if you are using a robots.txt file then you absolutely need to make sure that how Google sees your page and how website visitors see it is the same!
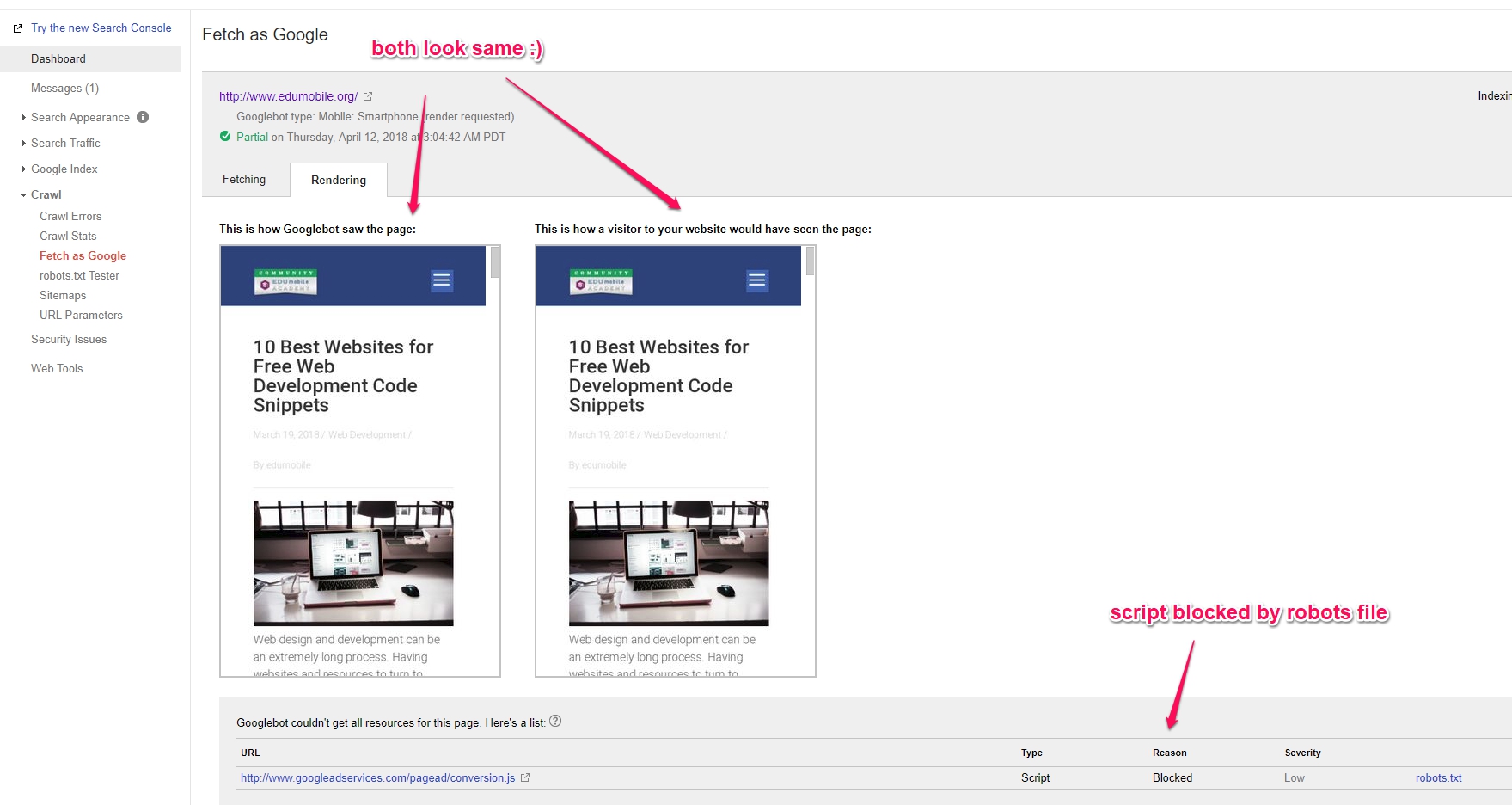
And, if your pages don’t look the same to Google and Visitors – Google could demote you!
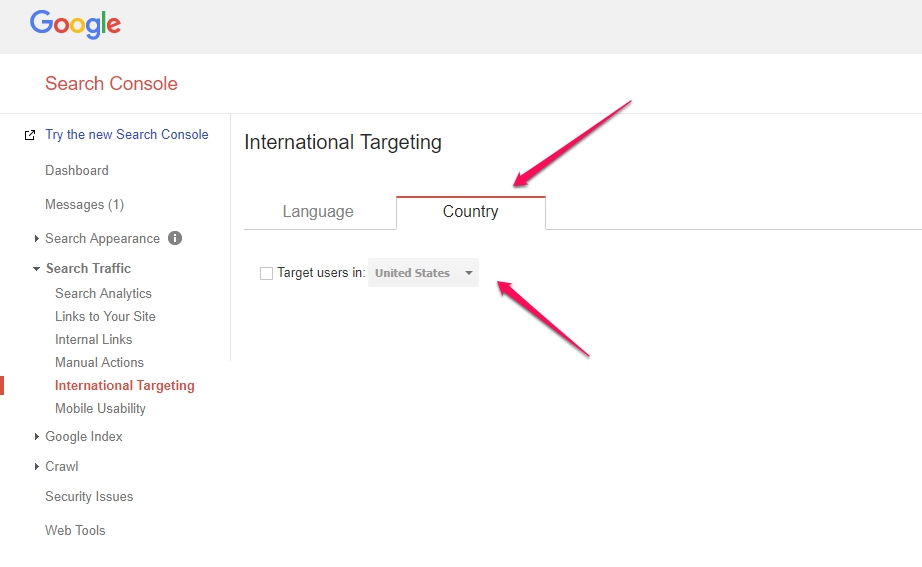
Geo-Targeting
Geo-targeting basically tells Google which country to rank your site for primarily and what language.
There are multiple ways to get this done…
- HREFlang
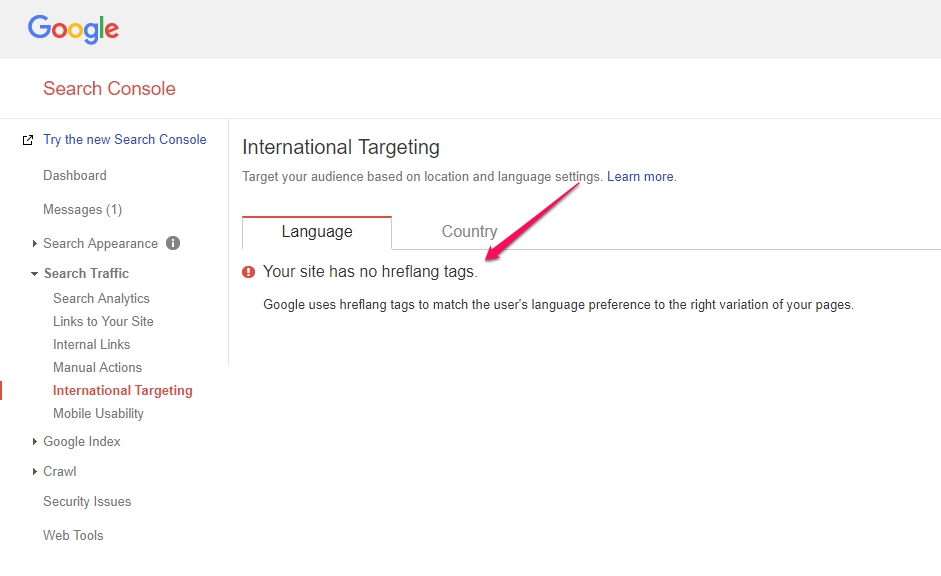
- Putting your site on a country level domain suffix (CCTLD – Country Code Top Level Domain)
- Search Console Setting… check hreflang code on site and check which country it targets – preferably leave default setting unless you want a specific country. The country you choose here will give you a boost in that country.
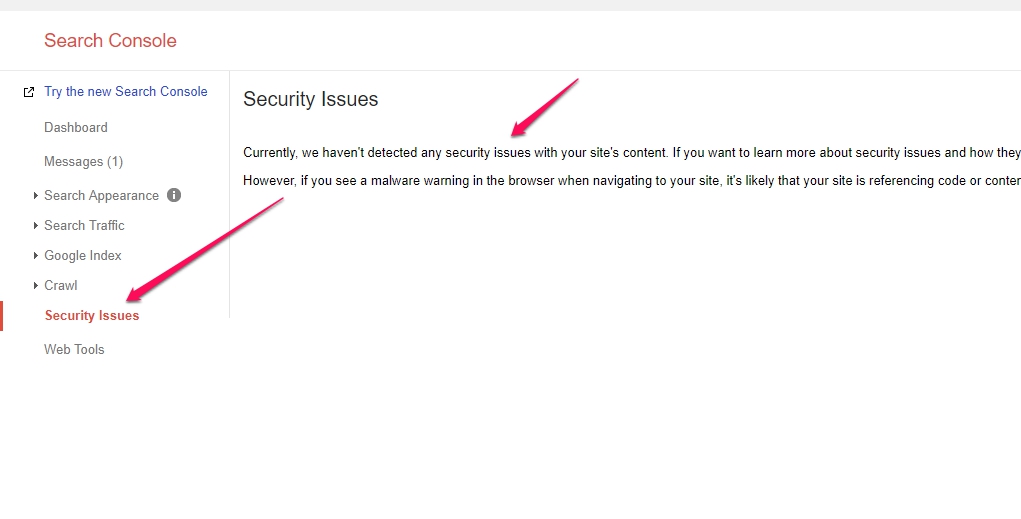
Server & Website Hacks
A server hack or attack on your website could happen in multiple ways.
- DDOS attack on your server
- Content injection on page (hacker inserts links and content on your site)
- Hackers can point backlinks to pages without Canonical code (which is why its important to have canonical on all pages) and add URL parameters at the end of the page like ?abc=viagra and thereby create multiple duplicate pages on your site in the eyes of Google.
- If they make robots.txt respond with 50x code (which is why you must access your robots.txt file and see that it is giving you a 200 response code). If they hack and manage to let it respond with 50x code error – then they can de-rank your site – as Google wont know which pages to index and rank.
How to check if there are issues? In search console you can check Server Security issues. However, this can only check for content injection issues.
Sitemaps
Having a sitemap is NOT important!
This is contrary to what majority SEOs will tell you! But, it is the truth!
You cannot make Google crawl your site faster… they want to crawl your site naturally in their way by following links and navigation.
In fact, if you have a sitemap and you get it wrong (sitemap has errors) – it will hurt you more!
If you have a site with a million new pages a day – then you may need a sitemap… otherwise it is not required at all!
Duplicate Content Issues
This is only an issue if your text is duplicated across many pages.
A simple way to check simple paragraphs for their uniqueness, is to cut and paste text from a paragraph on a page and paste it into Google Search!
If you want to do this in large numbers for your entire site and check for duplicate issues – then you could use free tool Duplichecker or the premium Copyscape tool.
The trick is you never want to give Google a choice which page to rank when it sees duplicate content. It should simply show you the original content page ranking on top.
We’re Done!
So that was all the steps to get the technical steps done for a website SEO audit. This system can be applied for local niche sites, national sites , ecommerce seo or for any type of seo project.
I’ll get to some more stuff and step by step walkthroughs like this. If you liked what you read, or have any questions – please drop me a comment below!
Hello Vishal,
I am a udemy student and just wanted to thank you for this post “SEO Audit Guide”. When you have a full course, let me know bcos I am always hunting for business opportunities and SEO auditing sounds good. Anything can be learned. I wish to lean from you. Thanks
Chuks
interesting
thanks